Descrição
XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating cross-lingual question answering performance. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 (Rajpurkar et al., 2016) together with their professional translations into ten languages: Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. Consequently, the dataset is entirely parallel across 11 languages.
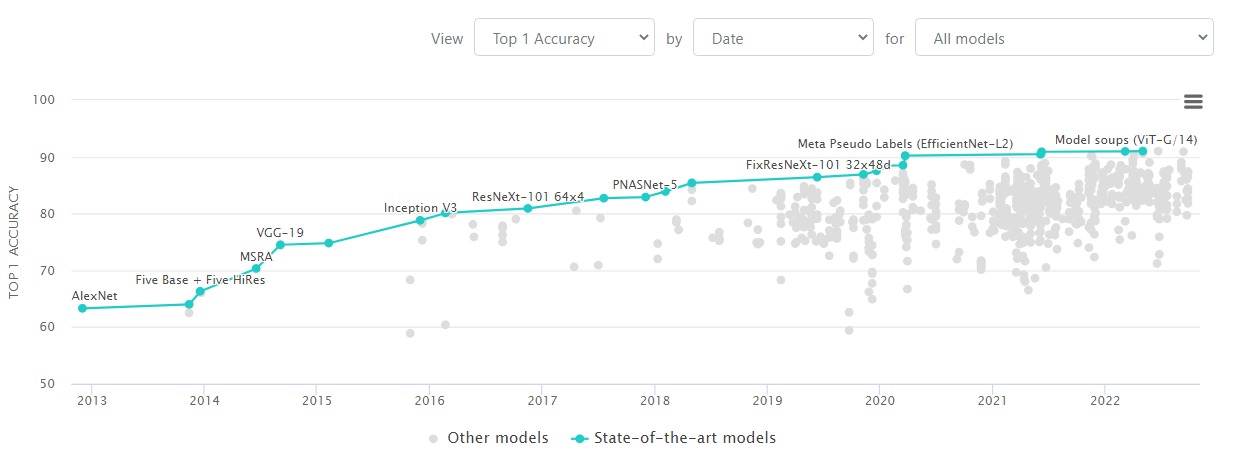
An Introduction to Papers With Code: What It is And How to Use It

PDF] mMARCO: A Multilingual Version of the MS MARCO Passage

MED Dataset Papers With Code

Token-level statistics of the constructed datasets. Average Length
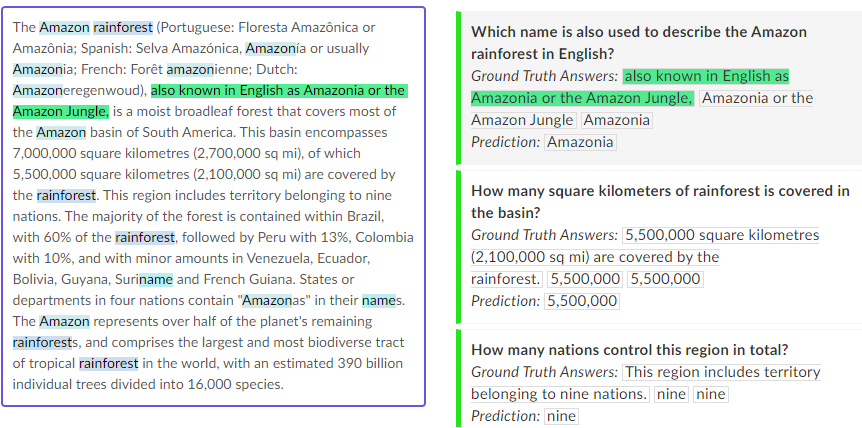
End to End Question-Answering System Using NLP and SQuAD Dataset

Results reported on TrecQA, WikiQA, and SQUAD-Sent datasets. SQUAD

ArxivPapers Dataset

The OIG Dataset
bccd TensorFlow Datasets

How to Answer Questions with Machine Learning
de
por adulto (o preço varia de acordo com o tamanho do grupo)



.jpg)